Key takeaways
- Query fan-out is the process where AI search engines decompose one user prompt into 8-12 parallel sub-queries before synthesizing a response -- and each platform does this differently.
- ChatGPT and Claude lean on parametric (training) knowledge, so they reward semantic depth, topic authority, and entity coverage rather than real-time freshness.
- Perplexity and Gemini use retrieval-augmented generation (RAG), meaning they pull live sources -- which makes factual consensus, link freshness, and modular passage structure more important.
- A December 2025 Surfer SEO study of 173,902 URLs found that 68% of pages cited in AI Overviews were NOT in the top 10 organic results -- fan-out explains why.
- Optimizing for one platform's fan-out pattern won't automatically transfer to the others. You need platform-aware content strategy.
What query fan-out actually is
When you type "best project management tools for remote teams" into an AI search engine, the system doesn't look up that exact phrase. It breaks your query into a cluster of sub-queries -- something like "top project management software 2026," "remote team collaboration features," "PM tool pricing comparison," and "enterprise vs small team project management" -- fires them in parallel, then synthesizes everything into one answer.
That's query fan-out. One prompt in, 8 to 12 retrieval queries out.
This matters enormously for content strategy. If your page only answers the original query, you might satisfy one sub-query out of ten. The AI engine will cite whoever answers the most sub-queries most clearly. That's why traditional SEO rankings and AI citations diverge so sharply -- they're measuring different things.
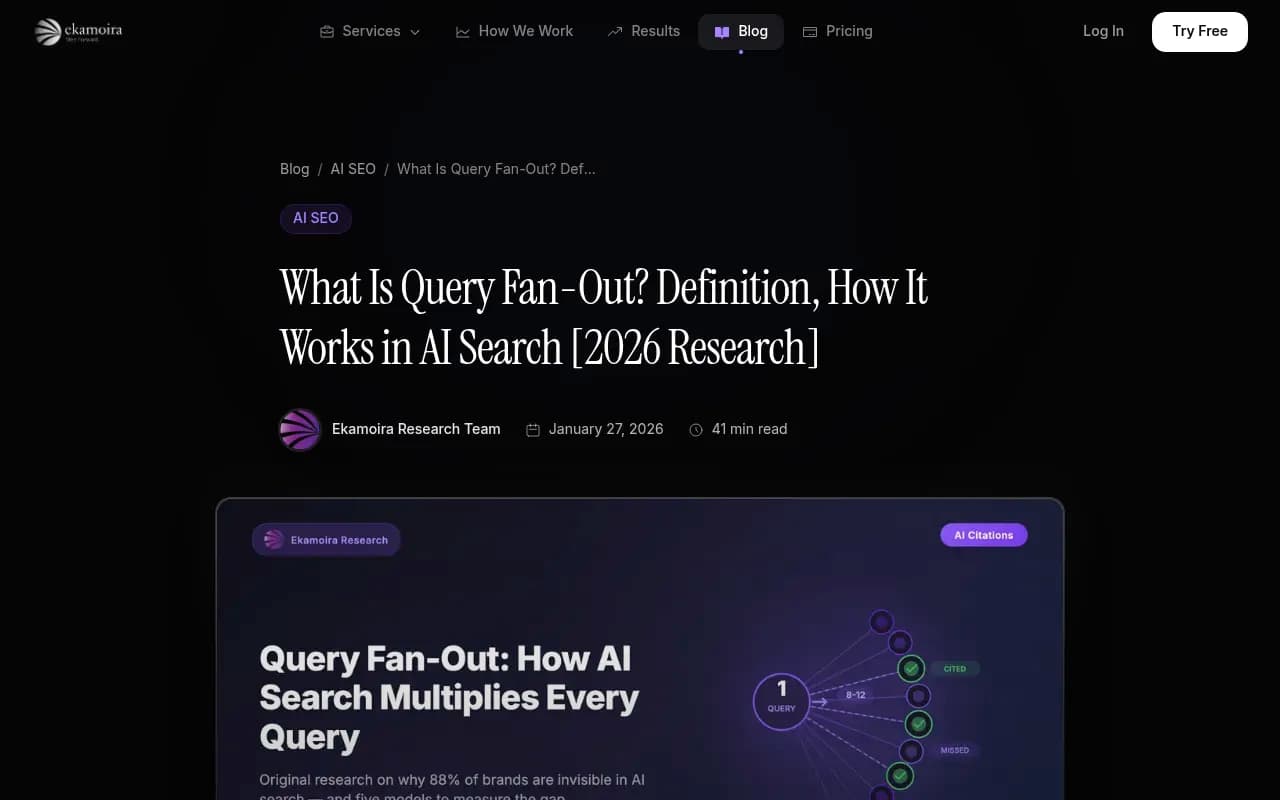
The disconnect is real. Research from Ekamoira analyzing AI citation patterns found that brands optimizing only for traditional search miss approximately 88% of AI citation opportunities. Fan-out is the core mechanism behind that gap.
How each platform handles fan-out differently
The four major AI engines -- ChatGPT, Perplexity, Claude, and Gemini -- all use fan-out, but they decompose queries differently, retrieve from different sources, and weight different signals when deciding what to cite.
ChatGPT
ChatGPT's fan-out behavior is heavily shaped by its parametric knowledge base. When it decomposes a query, it's often drawing on what it already "knows" rather than firing live web searches (unless you're using the browsing mode or a tool-enabled version).
This has a specific implication: ChatGPT tends to generate more sub-queries than Perplexity or Grok in many cases, according to data from Peec AI's analysis of fan-out patterns. The sub-queries are often broader and more conceptual -- exploring the topic from multiple angles rather than just hunting for fresh facts.
What ChatGPT rewards in cited content:
- Semantic depth and topical authority (covering a subject comprehensively, not just shallowly)
- Entity associations -- being clearly connected to the right concepts, brands, and categories in training data
- Consistent mentions across authoritative sources (this builds the parametric signal over time)
- Structured content that maps cleanly to common question patterns
One important caveat: API-based data and what users actually see in ChatGPT's interface can differ. Research comparing API outputs to scraped user-facing results found meaningful gaps -- which means testing in the actual product, not just through the API, matters.
Perplexity
Perplexity is fundamentally different from ChatGPT in one key way: it's a retrieval-first system. Every query triggers live web searches. Fan-out here means decomposing the prompt into sub-queries that each go out to the live web, with results synthesized in real time.
This makes Perplexity's citation behavior much closer to a traditional search engine -- but with the synthesis layer on top. What it rewards:
- Factual consensus across multiple sources (if three credible sites say the same thing, Perplexity is more likely to cite it)
- Fresh content -- publication date and recency matter more here than on ChatGPT
- External mentions and digital PR -- being cited by other sites helps Perplexity find and trust you
- Clear, extractable facts rather than long narrative passages
Because Perplexity is retrieval-augmented, self-promotion doesn't work. You need third-party validation. A brand that appears in comparison articles, review roundups, and industry publications will outperform a brand with great owned content but few external mentions.
Claude
Claude sits closer to ChatGPT on the parametric vs. retrieval spectrum, though Anthropic has been expanding its tool-use and web search capabilities. In its default mode, Claude relies heavily on training knowledge.
Claude's fan-out tends to be more conservative in volume -- it generates fewer sub-queries but goes deeper on each one. The model has a strong preference for nuanced, well-reasoned content over keyword-dense pages. It's also more likely to cite content that takes a clear position or provides original analysis rather than aggregating existing information.
What Claude rewards:
- Original analysis and clear editorial voice
- Long-form, well-structured content with logical flow
- Content that addresses counterarguments or acknowledges complexity
- Strong entity associations built through training data over time
Claude is harder to "optimize" for in the short term precisely because it depends on parametric knowledge. Getting cited by Claude often requires building genuine authority over months -- appearing in the kinds of sources that make it into training data.
Gemini
Gemini's fan-out behavior is arguably the most aggressive of the four. Google's research into "query fan-out" (sometimes called "multi-step query decomposition" in their documentation) shows that Gemini splits a single prompt into micro-intents -- very specific, narrow sub-queries that each target a distinct aspect of the user's question.
This micro-intent decomposition has a specific structural implication: Gemini rewards modular content. Specifically, 40-60 word passages that each answer one discrete question tend to perform better than long narrative paragraphs. If your content is written as flowing prose, Gemini may struggle to extract the specific passage it needs for a given sub-query.
What Gemini rewards:
- Modular, passage-level answers (think FAQ-style sections, not long essays)
- Real-time freshness -- Gemini uses RAG and pulls live sources
- Structured data and schema markup (Google's systems are tuned for this)
- Content that maps to specific micro-intents rather than broad topic coverage
A research project that extracted 60,000+ fan-out queries from the Gemini API found that the decomposition patterns are consistent but can differ from what users see in the actual Gemini interface -- another reminder that API testing alone isn't sufficient.
Platform comparison at a glance
| Dimension | ChatGPT | Perplexity | Claude | Gemini |
|---|---|---|---|---|
| Primary retrieval method | Parametric (+ optional web) | RAG / live web | Parametric (+ optional web) | RAG / live web |
| Fan-out volume | High (8-12+ sub-queries) | Medium-high | Medium (fewer, deeper) | High (micro-intent focused) |
| Content freshness weight | Low-medium | High | Low | High |
| Ideal passage length | Medium-long (semantic depth) | Short-medium (extractable facts) | Long-form (analysis) | Short (40-60 words per module) |
| External citation weight | Medium | High | Medium | Medium-high |
| Structured data benefit | Low | Low | Low | High |
| Hardest to optimize for quickly | No | No | Yes | No |
Why this creates a content strategy problem
Most content teams write one piece of content and hope it works everywhere. The fan-out differences above make that approach increasingly ineffective.
A long-form, narrative-style analysis piece might perform well for Claude citations but get ignored by Gemini's micro-intent decomposition. A highly modular FAQ page might get picked up by Gemini but lack the semantic depth ChatGPT needs to build entity associations. A piece with no external validation might rank fine in traditional search but get skipped by Perplexity entirely.
The practical implication: you need to think about content structure at the passage level, not just the page level. Each major section of a page should be able to stand alone as an answer to a specific sub-query. That serves both the modular platforms (Gemini) and the deeper-reading platforms (ChatGPT, Claude).
The dual-path optimization framework
Given that platforms split roughly into parametric (ChatGPT, Claude) and retrieval-augmented (Perplexity, Gemini), a useful mental model is to optimize along two paths simultaneously:
Path 1: Semantic authority (for parametric platforms)
- Build comprehensive topic coverage, not just individual pages
- Create consistent entity associations through owned and earned content
- Prioritize depth and original analysis over recency
- Think in terms of months-long authority building, not quick wins
Path 2: Retrieval optimization (for RAG platforms)
- Write modular, extractable passages (40-60 words per discrete answer)
- Earn external mentions and citations from credible third-party sources
- Keep content fresh -- update dates and facts matter
- Use structured data where possible (especially for Gemini)
Neither path alone is sufficient. A brand that's well-optimized for parametric platforms but invisible in live search results will miss Perplexity and Gemini citations. A brand that's great at earning external links but has thin, shallow owned content will struggle with ChatGPT and Claude.
Tracking fan-out visibility across platforms
Understanding how each platform decomposes your target queries is one thing. Knowing whether your content is actually getting cited across those fan-out sub-queries is another problem entirely.
This is where monitoring tools become necessary. Promptwatch tracks how AI engines actually behave in their user-facing interfaces (not just APIs), which matters because -- as the research shows -- API outputs and real user-facing citations can differ significantly. It also includes query fan-out data showing how prompts branch into sub-queries, so you can see exactly which angles your content is covering and which it's missing.

For teams that want to track visibility across specific platforms, there are several other tools worth knowing:

Peec AI has published some of the most detailed public research on ChatGPT fan-out patterns specifically, and their platform tracks fan-out behavior across ChatGPT, Perplexity, and Grok.
Otterly.AI

Otterly.AI covers ChatGPT, Perplexity, and Google AI Overviews -- useful if those three are your primary targets.
Profound

Profound is an enterprise-focused option that tracks brand mentions across 9+ AI engines with a strong emphasis on citation analysis.
What the research actually shows about fan-out volume
The numbers here are worth sitting with. A December 2025 study by Surfer SEO analyzed 173,902 URLs across 10,000 keywords and found that 68% of pages cited in AI Overviews were not in the top 10 organic results. That's not a small discrepancy -- it means traditional SEO rankings and AI citations are largely independent signals.
The Ekamoira research team's analysis goes further, estimating that brands optimizing only for traditional search miss approximately 88% of AI citation opportunities. The math behind this: if a query fans out into 10 sub-queries and your content only addresses the original query, you're competing for one citation slot out of ten.
One more data point worth noting: 73% of fan-out queries change with every search, according to Ekamoira's research. This means fan-out isn't deterministic -- the same prompt can decompose differently across sessions, which is why topical breadth matters more than optimizing for any single sub-query.
Practical content recommendations by platform
For ChatGPT visibility
Build topic clusters, not standalone pages. ChatGPT's parametric knowledge rewards brands that appear consistently across a topic area. One great page helps less than ten good pages that collectively establish authority. Focus on entity associations -- make sure your brand is clearly connected to the right categories, use cases, and comparisons in your content.
For Perplexity visibility
Invest in digital PR and third-party mentions. Perplexity's retrieval-first approach means it's looking for factual consensus across sources. Getting mentioned in industry roundups, comparison articles, and credible third-party reviews matters more here than on any other platform. Also keep your content fresh -- update statistics, publication dates, and examples regularly.
For Claude visibility
Write for depth and original analysis. Claude responds well to content that takes a clear position, acknowledges complexity, and provides genuine insight rather than aggregated information. This is the platform where "me too" content performs worst. Long-form, well-reasoned pieces with a distinct editorial voice tend to do better.
For Gemini visibility
Structure content at the passage level. Each section should answer one specific question in 40-60 words before expanding. Use headers liberally, implement FAQ schema where appropriate, and think about how a retrieval system would extract a specific passage from your page. Gemini's micro-intent decomposition means it's looking for very specific answers, not comprehensive overviews.
The bottom line
Query fan-out isn't a single behavior -- it's a family of behaviors that varies meaningfully across platforms. ChatGPT generates more sub-queries but relies on parametric knowledge. Perplexity retrieves live sources and weights factual consensus. Claude goes deeper on fewer sub-queries and rewards original analysis. Gemini decomposes into micro-intents and rewards modular, extractable passages.
The brands that will win AI search visibility in 2026 are the ones that stop treating all AI engines as interchangeable and start building content strategies that account for these differences. That means writing for passage-level extraction, building topical authority over time, earning external citations, and tracking which platforms are actually citing you -- and which aren't.
Tools like Promptwatch can surface the specific prompts where competitors are visible but you're not, which is a practical starting point for closing the gap.