Key takeaways
- Visibility percentage (how often your brand appears in AI responses) is the foundation metric -- without it, nothing else matters
- Citation count and source diversity tell you whether AI models are actually pulling from your content or just mentioning your name
- Sentiment and accuracy scores reveal what AI says about you, not just whether it mentions you
- Competitive share of voice shows your relative position, not just your absolute numbers
- Traffic attribution from AI is systematically undercounted in Google Analytics -- you need supplementary methods
- Answer gap analysis is the bridge between measurement and action: it shows exactly which prompts you're losing and why
Most marketing teams measuring AI search visibility are measuring the wrong things. They're watching referral traffic from ChatGPT tick up in GA4, calling it a win, and moving on. The problem is that AI-referred traffic is only a fraction of AI's actual influence on your pipeline. When someone asks Perplexity which CRM to buy and your competitor gets recommended, that person might Google your competitor's name next, visit their site directly, and convert -- and your analytics will show zero signal from AI.
The measurement gap is real, and it's getting wider. AirOps research found that only 30% of brands maintain consistent visibility from one AI answer to the next, and just 20% stay visible across five consecutive runs of the same prompt. That level of volatility makes one-off manual checks useless. You need a framework.
Here are the seven metrics that actually tell you whether you're winning in AI search -- what they measure, why they matter, and how to track them.
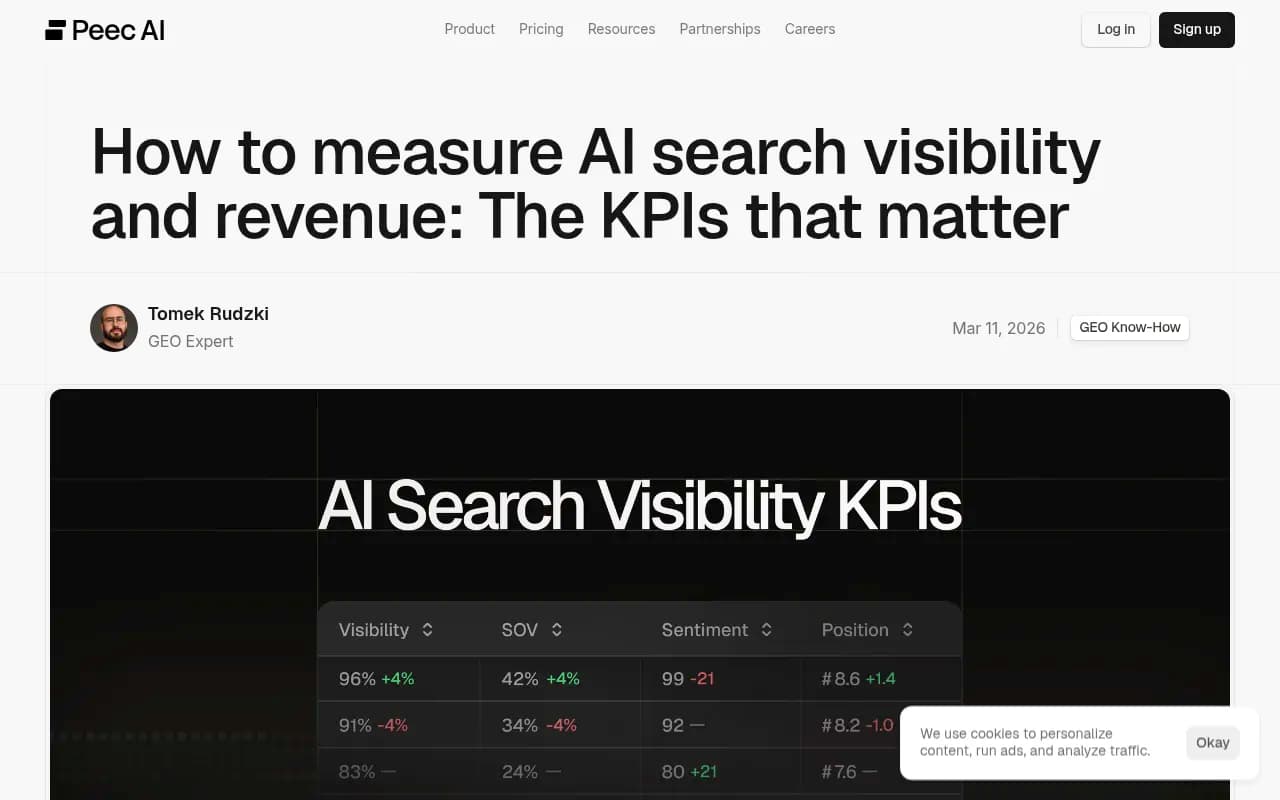
1. Visibility rate (share of prompts where you appear)
This is the foundation. Before anything else, you need to know: does your brand show up at all?
Visibility rate measures the percentage of relevant prompts where an AI model mentions your brand in its response. If you track 100 prompts relevant to your category and your brand appears in 34 of them, your visibility rate is 34%.
The number sounds simple, but the execution isn't. A few things make it tricky:
- AI responses vary between runs of the same prompt. Ask ChatGPT the same question twice and you may get different sources cited. This is why single-run checks are meaningless -- you need multiple runs per prompt to get a stable estimate.
- "Relevant prompts" requires deliberate prompt design. Broad prompts ("what's a good CRM?") behave differently from buyer-intent prompts ("what CRM should a 50-person B2B SaaS company use?"). Your prompt set should reflect how your actual buyers phrase questions.
- Visibility varies by model. You might appear consistently in Perplexity but rarely in ChatGPT, or vice versa. Tracking one model and assuming it represents "AI search" is a mistake.
A reasonable benchmark for an established brand in a competitive category: 20-40% visibility rate across a well-designed prompt set. Below 10% is a warning sign. Above 60% is strong.
Tools like Promptwatch track visibility rates across 10 AI models simultaneously, running prompts repeatedly to account for response variability.

2. Citation rate and source diversity
Visibility tells you your brand was mentioned. Citation rate tells you whether AI is actually pulling from your content.
There's a meaningful difference between an AI model saying "Company X is a popular option" (a brand mention) and "According to Company X's 2026 benchmark report..." (a citation with a source). The second is far more valuable -- it means AI is treating your content as a reference, not just your name as a known entity.
Citation rate measures how often your specific URLs appear as cited sources in AI responses. Source diversity measures how many different pages on your site are being cited, not just your homepage.
Why does source diversity matter? If AI models only ever cite your homepage, you're visible but fragile. A brand whose blog posts, research pages, comparison pages, and product pages all get cited has much deeper AI presence -- and is harder to displace.
What drives citation rates? A few patterns hold up consistently:
- Original data and research gets cited more than opinion pieces
- Structured content (clear headers, numbered lists, defined terms) is easier for AI to extract and attribute
- Fresh content matters -- AI models weight recency, especially for fast-moving topics
- Schema markup helps AI understand what a page is about and who published it
3. Brand sentiment in AI responses
You can be mentioned in 80% of relevant AI responses and still be losing. If AI consistently frames your brand as "the expensive option" or "better suited for enterprise" when your buyers are SMBs, visibility is working against you.
Sentiment analysis in AI search isn't the same as social media sentiment. You're not counting positive vs. negative tweets. You're analyzing the specific language AI models use when describing your brand -- the adjectives, the comparisons, the caveats, the positioning relative to competitors.
Concretely, you want to track:
- Is your brand described accurately? (If AI says you don't support a feature you've had for two years, that's an accuracy problem, not just a sentiment problem)
- What context does AI use when recommending you? ("Great for X but not ideal for Y" -- is that Y something your buyers care about?)
- How does AI describe you relative to competitors? Are you positioned as the premium option, the budget option, the technical option?
Sentiment problems are often content problems. If AI consistently mischaracterizes your product, it's usually because the content AI is drawing from -- your own site, third-party reviews, Reddit discussions -- doesn't clearly address that topic. The fix is content, not PR.

4. Competitive share of voice (AI SOV)
Your visibility rate in isolation doesn't tell you much. 34% sounds fine until you learn your main competitor is at 71% for the same prompt set.
AI share of voice measures your brand's visibility relative to competitors across the same set of prompts. It's the AI equivalent of traditional share of voice, but the dynamics are different: AI responses typically surface 2-5 brands per answer, so the competition is more concentrated than in a traditional SERP with 10 blue links.
A few things to track within AI SOV:
- Which prompts are you winning? Where are you consistently recommended over competitors?
- Which prompts are you losing? Where do competitors appear and you don't?
- Which models favor which brands? Some brands do significantly better in Perplexity than in ChatGPT, often because of where their content is indexed and cited.
The "answer gap" -- prompts where competitors appear but you don't -- is where the real optimization work happens. Knowing you have a 34% visibility rate is descriptive. Knowing you're invisible for "best [category] for [specific use case]" prompts while your competitor owns them is actionable.
Profound

5. Response consistency score
This one doesn't get talked about enough. AI responses aren't deterministic -- the same prompt can produce meaningfully different answers across runs, models, and time. A brand that appears in 80% of runs is in a very different position than one that appears in 30% of runs, even if both show up in a single manual check.
Response consistency measures how stable your brand's presence is across:
- Multiple runs of the same prompt (same model, same day)
- The same prompt across different models (ChatGPT vs. Perplexity vs. Gemini)
- The same prompt over time (week-over-week, month-over-month)
Low consistency is a signal that your AI presence is fragile. You might be appearing because of a single piece of content that happens to rank well right now, rather than because you have deep, authoritative coverage of a topic. When that content ages or a competitor publishes something better, you'll drop out.
High consistency means AI models reliably associate your brand with a topic. That's the goal.
Tracking consistency requires running prompts at scale and over time -- not something you can do manually. This is where purpose-built AI visibility platforms earn their keep.
Otterly.AI

6. AI traffic attribution (direct and assisted)
Here's the uncomfortable truth about AI traffic measurement: most of it is invisible in your analytics.
When someone discovers your brand through ChatGPT, they rarely click a link in the chat interface. More often, they remember your name, open a new tab, and search for you on Google or type your URL directly. Google Analytics credits that session to "Google organic" or "direct" -- not to AI. The AI touchpoint disappears.
This means AI's influence on your pipeline is systematically undercounted. The brands that figure out how to measure it properly will have a significant advantage in budget allocation and strategy.
A few approaches that work:
- Watch for anomalies in direct traffic. If direct traffic spikes after a period of increased AI visibility for your brand, that's a signal. It's not proof, but it's a signal worth investigating.
- Use UTM parameters on any links you can control in AI-adjacent contexts (your own chatbot, AI-powered tools that cite you, etc.)
- Track "branded search" volume in Google Search Console. When AI mentions your brand, people often search for it. Rising branded search is a downstream indicator of AI visibility.
- Some platforms can connect AI crawler activity to actual site visits. If you see GPTBot crawling a page and then see a spike in direct traffic to that page, there's a plausible connection.
Platforms like Promptwatch offer AI crawler logs that show exactly which pages AI agents are reading, how often, and when those pages move from crawl to citation -- giving you the closest thing to a complete attribution picture currently available.
7. Answer gap score (the metric that drives action)
The first six metrics tell you where you stand. The answer gap score tells you what to do about it.
Answer gap analysis maps the specific prompts where competitors are visible and you're not. It's not a single number -- it's a structured view of your visibility blind spots, organized by topic, intent, and competitive position.
Why is this the most actionable metric? Because it converts "we need to improve AI visibility" (vague) into "we need content that answers these 12 specific questions that buyers ask in the consideration phase" (specific). You can brief a writer, assign a content sprint, and track whether the new content gets cited.
The answer gap score can be thought of as the ratio of prompts where competitors appear without you to the total prompt set. A high answer gap score means you're leaving a lot of ground uncovered. As you publish content that addresses those gaps and AI models start citing it, the score should fall.
This is the metric that connects AI visibility measurement to revenue impact. Closing answer gaps in high-intent prompts (comparison queries, "best for X" queries, use-case-specific queries) is where AI visibility translates into pipeline.
How the metrics fit together
These seven metrics aren't independent -- they form a diagnostic framework:
| Metric | What it tells you | Primary use |
|---|---|---|
| Visibility rate | Are you in the room? | Baseline health check |
| Citation rate & source diversity | Is AI using your content? | Content quality signal |
| Brand sentiment | What is AI saying about you? | Positioning and accuracy |
| Competitive AI SOV | How do you compare? | Competitive benchmarking |
| Response consistency | Is your presence stable? | Fragility assessment |
| AI traffic attribution | Is visibility driving pipeline? | Revenue connection |
| Answer gap score | What's missing? | Content prioritization |
Start with visibility rate and competitive SOV to understand the scale of the problem. Use citation rate and consistency to diagnose why you're visible or invisible. Use sentiment to check whether visibility is helping or hurting. Use traffic attribution to connect it to revenue. Use answer gap analysis to decide what to build next.
Tools worth knowing
A handful of platforms have built measurement capabilities specifically for AI search. They vary significantly in depth:
Profound
Otterly.AI

Most monitoring-only tools handle metrics 1-5 reasonably well. Where they diverge is metrics 6 and 7: traffic attribution and answer gap analysis require deeper infrastructure -- crawler log access, content gap analysis, and the ability to connect visibility data to actual site behavior. If you're serious about connecting AI visibility to revenue, look for platforms that go beyond dashboards into action.
One thing most teams get wrong
They measure AI visibility the same way they used to measure keyword rankings: check it once, note the number, move on.
AI responses are probabilistic and volatile. A brand that appears in 70% of runs of a prompt this week might drop to 40% next week because a competitor published a better piece of content, because an AI model updated its training data, or because the prompt phrasing shifted slightly. The only way to catch these changes is continuous monitoring with enough prompt volume to detect real trends versus noise.
The teams winning in AI search in 2026 are running structured prompt sets, tracking all seven metrics consistently, and using answer gap analysis to drive their content calendar. That's the loop: measure, find gaps, create content, measure again.
It's not complicated. But it does require treating AI visibility as a discipline, not an afterthought.