Key Takeaways
- Braintrust is the strongest all-around alternative—end-to-end platform with production tracing, auto-evals, and prompt management at competitive pricing ($249/mo Pro vs Maxim's $29/seat)
- Langfuse offers the best open-source option with full self-hosting, OpenTelemetry tracing, and DSPy integration—ideal for teams wanting control and transparency
- LangSmith is best for LangChain-native teams needing deep integration with the LangChain ecosystem, though it's monitoring-focused without built-in content generation
- Arize AI leads for enterprise teams requiring advanced agent evaluation, automated prompt optimization, and built-in guardrails—used by DoorDash, Uber, and Reddit
- LangWatch excels at pre-production agent testing with synthetic user simulations and batch evaluations, plus DSPy auto-optimization for continuous improvement
Maxim AI positions itself as an end-to-end evaluation and observability platform for AI agents, promising to help teams ship 5x faster with simulation, evaluation, and monitoring capabilities. But the LLM tooling landscape has matured rapidly—teams now have multiple strong alternatives offering different trade-offs in features, pricing, and deployment flexibility.
The most common reasons teams look beyond Maxim AI: needing open-source transparency and self-hosting options, wanting deeper integration with specific frameworks like LangChain, requiring more advanced agent simulation capabilities, or seeking platforms with stronger enterprise features like automated prompt optimization and guardrails. Some teams also find Maxim's per-seat pricing model ($29-49/seat/month) less predictable than usage-based or flat-rate alternatives.
This guide compares eight leading alternatives across evaluation capabilities, observability features, prompt management, pricing models, and deployment options. Each platform has carved out a distinct position—from pure open-source plays to enterprise-grade solutions with advanced automation.
Braintrust
Braintrust is an end-to-end AI observability platform that turns production traces into evaluations, compares prompts and models side-by-side, and helps teams improve quality with every release. Used by Coursera and other top AI teams, it provides real-time trace inspection, automated eval generation, and prompt versioning in a single unified platform.
What it does better than Maxim AI:
Braintrust's core strength is closing the loop between production monitoring and continuous improvement. Unlike Maxim's separate simulation/evaluation/observability modules, Braintrust automatically converts production traces into eval datasets—you see a failure in production, click a button, and it becomes a regression test. The platform also offers more sophisticated prompt comparison tools with A/B testing built directly into the UI, plus feature-flag-style rollout controls that Maxim lacks.
The evaluation framework is more flexible: you can write evals in code (Python/TypeScript), use LLM-as-judge, or combine both. Braintrust's auto-evals run continuously in the background, catching regressions before they hit production. The trace inspection UI is faster and more intuitive than Maxim's, with better filtering and search across millions of traces.
Pricing comparison:
Braintrust offers a free tier, then Pro at $249/month plus usage-based pricing for traces and evals. This is higher than Maxim's $29/seat entry point but includes unlimited team members—better for larger teams. Enterprise pricing is custom. The usage-based model can be more predictable than per-seat for teams with fluctuating headcount.
Trade-offs:
Braintrust doesn't offer the same level of pre-built agent simulation that Maxim advertises. If you need synthetic user conversations at scale before launch, you'll need to build that yourself or use another tool. Braintrust also lacks Maxim's "Bifrost" LLM gateway features—it's purely observability and evaluation, not routing or load balancing.
Best for: Teams that want a single platform for production monitoring and continuous evaluation, especially those who value automatic trace-to-eval conversion and sophisticated prompt versioning. Strong fit for mid-size to large engineering teams shipping customer-facing AI products.
LangSmith
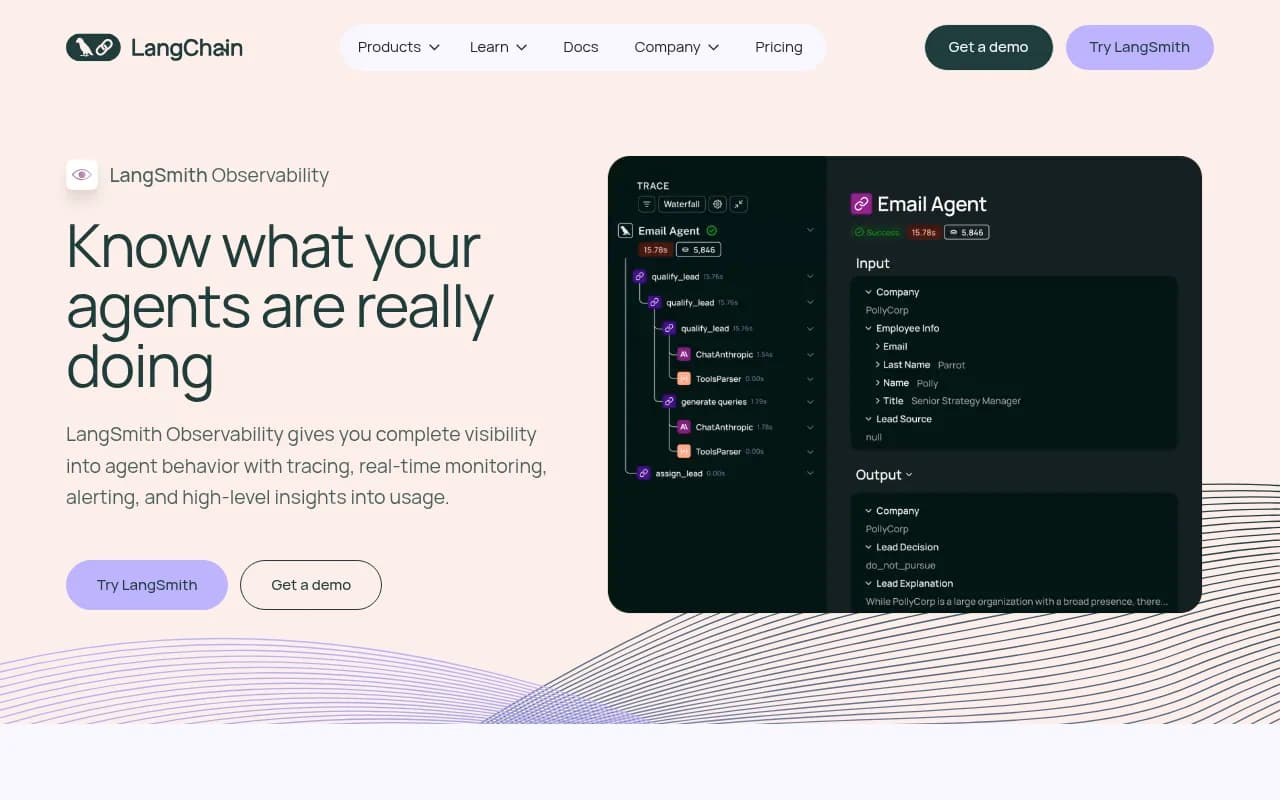
LangSmith is the observability and testing platform from LangChain, offering tracing, debugging, and performance analytics specifically designed for LangChain applications. Trusted by Klarna, GitLab, LinkedIn, and thousands of other teams, it provides deep integration with the LangChain ecosystem plus support for non-LangChain LLM calls.
What it does better than Maxim AI:
If you're building with LangChain, LangSmith's integration is unmatched—automatic tracing of chains, agents, and tools with zero configuration. The trace detail view shows the exact LangChain components involved (retrievers, tools, memory) in a way that generic observability platforms can't match. Debugging is faster because you see the LangChain abstractions, not just raw LLM calls.
LangSmith's dataset management is more mature than Maxim's. You can version datasets, share them across teams, and run experiments with different prompt/model combinations against the same test set. The playground lets you iterate on prompts with immediate feedback, then deploy changes directly to production with versioning.
The pricing model is more transparent: $39/month per seat plus usage-based trace pricing (vs Maxim's $29-49/seat with unclear usage limits). LangSmith also offers self-hosted enterprise deployments, which Maxim doesn't.
Trade-offs:
LangSmith is monitoring and evaluation-focused—it doesn't include agent simulation capabilities like Maxim advertises. You won't get synthetic user conversations or pre-production stress testing out of the box. The platform also lacks advanced features like automated prompt optimization or built-in guardrails that some alternatives offer.
While LangSmith supports non-LangChain applications, the experience is clearly optimized for LangChain users. If you're using raw OpenAI SDK, Anthropic, or other frameworks, you'll get basic tracing but miss the deeper insights.
Best for: Teams already using LangChain or LangGraph who want native integration and don't want to instrument tracing manually. Also strong for teams that need self-hosted deployments for compliance or data residency requirements.
Vellum
Vellum is a collaborative platform for prompt engineering and AI agent development that emphasizes conversational agent creation—you describe what you want and the platform helps you build it through chat. Used by product and sales teams alongside engineers, it provides testing, comparison, and deployment tools designed for cross-functional collaboration.
What it does better than Maxim AI:
Vellum's standout feature is accessibility for non-engineers. Product managers and domain experts can create and test agents without writing code, using the conversational interface to define workflows. This is fundamentally different from Maxim's engineer-first approach. The platform integrates with 40+ tools (Linear, Notion, Slack, Salesforce, etc.) out of the box, making it easier to build practical business automation agents.
The prompt playground is more visual and intuitive than Maxim's, with side-by-side comparison of multiple prompt variants and real-time testing. Vellum also offers better workflow orchestration—you can chain multiple LLM calls, tools, and conditional logic in a visual builder, then deploy the entire workflow as an API.
Pricing comparison:
Vellum starts at $25/month (Pro plan), which is cheaper than Maxim's $29/seat. However, the free tier is more limited. Enterprise pricing is custom. The pricing is per-user rather than usage-based, which can be more predictable for small teams.
Trade-offs:
Vellum is less focused on deep observability and evaluation compared to Maxim. You get basic tracing and metrics, but not the comprehensive production monitoring or automated evaluation pipelines that Maxim emphasizes. The platform is optimized for building and deploying agents quickly, not for rigorous testing and continuous improvement.
Vellum also lacks advanced features like agent simulation with synthetic users, automated prompt optimization, or built-in guardrails. It's a development and deployment platform, not a full LLMOps solution.
Best for: Cross-functional teams (product, sales, marketing, engineering) that want to build practical business automation agents quickly without deep ML expertise. Strong fit for companies building internal tools and workflows rather than customer-facing AI products.
Langfuse
Langfuse is an open-source LLM engineering platform providing end-to-end observability, prompt management, evaluation, and metrics for AI applications. Built on OpenTelemetry standards, it integrates with OpenAI, LangChain, LlamaIndex, LiteLLM, and other popular frameworks. Langfuse is the leading open-source alternative in this space, recently acquired by ClickHouse.
What it does better than Maxim AI:
Langfuse's biggest advantage is transparency and control—it's fully open source (MIT license) with a mature self-hosting option. You own your data, can audit the code, and aren't locked into a vendor. The OpenTelemetry-based tracing is more standardized than Maxim's proprietary approach, making it easier to integrate with existing observability stacks.
The prompt management system is more sophisticated: version control with Git-like diffs, A/B testing with statistical significance tracking, and rollback capabilities. Langfuse also offers better collaboration features—team members can annotate traces, create datasets from production data, and share evaluation results with stakeholders.
The evaluation framework is more flexible than Maxim's. You can run evals in Python or TypeScript, use LLM-as-judge, integrate with DSPy for automated optimization, or write custom scoring functions. The platform tracks eval results over time and surfaces regressions automatically.
Pricing comparison:
Langfuse offers a generous free tier (50k observation units/month, 30 days retention) that's more substantial than Maxim's free plan. The Pro plan is $59/month (vs Maxim's $29/seat), but includes 100k units and 90 days retention. Enterprise pricing is custom. Critically, the self-hosted version is completely free and includes all features—no artificial limitations.
Trade-offs:
Langfuse doesn't offer pre-built agent simulation capabilities like Maxim advertises. If you need synthetic user conversations at scale, you'll need to build that yourself or integrate with another tool. The platform also lacks Maxim's "Bifrost" LLM gateway features—no built-in routing, load balancing, or failover.
The UI, while functional, is less polished than commercial alternatives. Self-hosting requires more DevOps expertise—you're responsible for deployment, scaling, and maintenance. The managed cloud version is easier but still requires more configuration than turnkey solutions.
Best for: Teams that prioritize open source, data ownership, and deployment flexibility. Ideal for companies with compliance requirements, those building in regulated industries, or engineering teams that want to customize and extend the platform. Also strong for teams already using OpenTelemetry or ClickHouse.
Arize AI
Arize AI is an enterprise-grade AI and agent engineering platform used by DoorDash, Uber, Reddit, Booking.com, and 6,700+ teams. It provides unified observability, automated evaluations, prompt optimization, and real-time monitoring for LLM applications and AI agents—from development through production. Arize also offers Phoenix, a popular open-source observability tool.
What it does better than Maxim AI:
Arize's standout features are automated prompt optimization and built-in guardrails—capabilities Maxim doesn't offer. The platform runs four powerful optimizers (Few-shot Bayesian, MIPRO, evolutionary, and LLM-powered MetaPrompt) that automatically improve prompts based on your evaluation metrics. This is a step beyond manual prompt engineering—the system iterates to elite performance and freezes the results into production-ready assets.
The guardrails system screens user inputs and LLM outputs in real-time to stop unwanted content—PII detection, competitor mentions, off-topic discussions, toxicity, and more. You can use Arize's built-in models or integrate third-party guardrails libraries. This is critical for enterprise deployments but missing from Maxim entirely.
Arize's observability is more comprehensive: real-time agent tracing with detailed step-by-step breakdowns, automated anomaly detection, and production monitoring dashboards that surface issues before users report them. The platform also tracks ChatGPT Shopping and other AI recommendation channels—useful for e-commerce and marketplace companies.
Pricing comparison:
Arize's pricing isn't publicly listed but starts higher than Maxim—likely $99-249/month based on competitor positioning. However, the enterprise features (automated optimization, guardrails, advanced monitoring) justify the premium for larger teams. A free trial is available, and Phoenix (the open-source version) is completely free to self-host.
Trade-offs:
Arize is built for enterprise scale and complexity—it's overkill for small teams or simple use cases. The learning curve is steeper than Maxim's, and setup requires more configuration. If you just need basic tracing and evaluation, Arize's advanced features may be more than you need.
The platform is also more opinionated about architecture—it expects you to structure agents in specific ways to take full advantage of optimization and guardrails. This can be constraining if you have existing systems.
Best for: Enterprise teams shipping customer-facing AI agents at scale, especially in regulated industries or high-stakes applications (finance, healthcare, e-commerce). Strong fit for companies that need automated prompt optimization, real-time guardrails, and comprehensive production monitoring. Also ideal for teams that want both managed cloud and self-hosted options.
Comet Opik
Comet Opik is an open-source LLM evaluation platform that helps AI developers debug, test, and continuously improve LLM-powered applications through comprehensive tracing, evaluation metrics, automated prompt optimization, and production monitoring. Built by Comet (the ML experiment tracking company), it integrates with RAG systems, agents, and all major LLM frameworks.
What it does better than Maxim AI:
Opik's core strength is automated prompt optimization using DSPy and other advanced techniques. The platform runs four optimizers (Few-shot Bayesian, MIPRO, evolutionary, and MetaPrompt) that iterate on prompts based on your evaluation metrics, then freeze the best results into production-ready assets. This is similar to Arize's approach but with a more developer-friendly interface.
The evaluation framework is more comprehensive than Maxim's: pre-configured metrics for hallucination detection, factuality, moderation, and more, plus support for custom metrics in Python. Opik also offers better integration with CI/CD pipelines—you can run LLM unit tests (built on PyTest) on every deploy to catch regressions before they hit production.
The guardrails system is built-in and powerful: screen user inputs and LLM outputs for PII, competitor mentions, off-topic discussions, and toxicity using Opik's models or third-party libraries. This is a critical enterprise feature that Maxim lacks.
Pricing comparison:
Opik is completely free and open source for self-hosting—no feature limitations. The managed cloud version offers a free tier plus custom enterprise pricing. This is more accessible than Maxim's $29/seat entry point, especially for teams comfortable with self-hosting.
Trade-offs:
Opik is newer and less mature than alternatives like LangSmith or Braintrust—the ecosystem and community are still growing. Documentation is improving but not as comprehensive as established players. The UI, while functional, is less polished than commercial alternatives.
Opik also doesn't offer pre-built agent simulation capabilities like Maxim advertises. If you need synthetic user conversations at scale before launch, you'll need to build that yourself or integrate with another tool.
Best for: Teams that want automated prompt optimization and guardrails without paying enterprise prices. Ideal for developers comfortable with open source and self-hosting, especially those already using Comet for ML experiment tracking. Strong fit for teams building RAG systems or agents that need rigorous evaluation and continuous improvement.
Helicone

Helicone is an open-source AI Gateway and LLM observability platform that provides unified access to 100+ AI models through a single SDK, intelligent routing, real-time tracing, and comprehensive monitoring across all providers. Trusted by 1000+ AI teams including Duolingo and Singapore Airlines, it's designed to help developers build reliable AI applications with minimal code changes.
What it does better than Maxim AI:
Helicone's standout feature is the AI Gateway—unified access to 100+ models (OpenAI, Anthropic, Google, DeepSeek, Mistral, Groq, Together AI, AWS Bedrock, Azure, and more) through a single SDK. You switch providers by changing the model name—no code rewrites needed. This is fundamentally different from Maxim's approach, which focuses on evaluation and observability but doesn't provide routing or gateway capabilities.
The gateway includes intelligent features like automatic fallbacks (if one provider is down, route to another), load balancing across providers, rate limiting, and cost optimization (automatically route to the cheapest model that meets your quality threshold). These are critical for production reliability but missing from Maxim entirely.
Helicone's observability is real-time and comprehensive: trace every LLM call across all providers, monitor latency and costs, and debug failures with detailed logs. The platform also offers better caching—automatically cache responses to reduce costs and latency for repeated queries.
Pricing comparison:
Helicone offers a generous free tier (100k requests/month) that's more substantial than Maxim's free plan. The Pro plan is $20/seat/month (vs Maxim's $29/seat) with unlimited requests. Enterprise pricing is custom. The open-source self-hosted version is completely free.
Trade-offs:
Helicone is primarily a gateway and observability platform—it doesn't offer the same depth of evaluation and testing capabilities as Maxim. You get basic tracing and monitoring, but not automated evaluations, agent simulations, or prompt optimization. If you need rigorous testing and continuous improvement workflows, you'll need to integrate additional tools.
The platform is also more infrastructure-focused than product-focused. It's built for engineers who want control over routing and reliability, not for product teams who want to iterate on prompts and test agents.
Best for: Teams that need unified access to multiple LLM providers with intelligent routing, fallbacks, and cost optimization. Ideal for production applications that require high reliability and want to avoid vendor lock-in. Strong fit for engineering teams that prioritize infrastructure and observability over evaluation and testing.
LangWatch
LangWatch is an end-to-end AI agent testing, LLM evaluation, and observability platform used by thousands of AI engineering teams. It helps developers stress-test agents pre-production with synthetic simulations, run batch evaluations, monitor live LLM interactions, and optimize prompts using DSPy—all in a single platform designed for continuous quality improvement.
What it does better than Maxim AI:
LangWatch's core strength is pre-production agent testing with synthetic user simulations. The platform runs thousands of synthetic conversations across scenarios, languages, and edge cases—testing your agent's behavior before real users see it. This is more comprehensive than Maxim's simulation capabilities, with better support for multi-turn conversations, tool usage validation, and edge case coverage.
The evaluation framework is more flexible: create custom evals that measure quality specific to your product, use LLM-as-judge for complex issues like hallucination detection, or integrate with DSPy for automated prompt optimization. LangWatch also offers better collaboration features—domain experts and engineers can work together to define evaluations, review results, and label production data.
The platform includes automated DSPy optimization that continuously improves prompts based on your evaluation metrics. This is similar to Arize and Opik's approach but with a more intuitive interface and better integration with the testing workflow.
Pricing comparison:
LangWatch offers a free developer plan with full features. Paid plans start at €59/month (Professional) with unlimited evaluations, agent simulations, and DSPy optimization. This is competitive with Maxim's $29/seat pricing, especially considering the unlimited usage. Enterprise plans with custom pricing are available for on-prem deployment and SLA guarantees.
Trade-offs:
LangWatch is newer and less mature than alternatives like LangSmith or Braintrust—the ecosystem and community are still growing. The platform is also more focused on testing and evaluation than production monitoring—you get basic observability, but not the comprehensive real-time monitoring and alerting that some alternatives offer.
LangWatch also lacks gateway features like intelligent routing, load balancing, or failover. It's purely a testing, evaluation, and observability platform, not an infrastructure solution.
Best for: Teams that want comprehensive pre-production agent testing with synthetic user simulations. Ideal for developers building complex multi-turn conversational agents or RAG systems that need rigorous evaluation before launch. Strong fit for teams that value collaboration between engineers and domain experts, and those who want automated prompt optimization with DSPy.
How to Choose the Right Alternative
The best Maxim AI alternative depends on your team's priorities and constraints:
If you need the strongest all-around platform: Choose Braintrust. It offers the best balance of production monitoring, automated evaluations, and prompt management with intuitive trace-to-eval conversion and sophisticated versioning.
If you want open source and full control: Choose Langfuse. It's the most mature open-source option with comprehensive features, OpenTelemetry standards, and no vendor lock-in. Self-hosting is free and fully featured.
If you're building with LangChain: Choose LangSmith. The native integration is unmatched, and you'll get deeper insights into chains, agents, and tools than generic platforms provide.
If you need enterprise features like automated optimization and guardrails: Choose Arize AI. It's built for scale with advanced capabilities that justify the premium pricing—automated prompt optimization, real-time guardrails, and comprehensive production monitoring.
If you want comprehensive pre-production agent testing: Choose LangWatch. The synthetic user simulations are more thorough than alternatives, with better support for multi-turn conversations and edge case coverage.
If you need unified access to 100+ models with intelligent routing: Choose Helicone. The AI Gateway features (fallbacks, load balancing, cost optimization) are critical for production reliability and missing from other platforms.
If you want automated prompt optimization without enterprise pricing: Choose Comet Opik. It's free and open source with powerful DSPy-based optimization and built-in guardrails.
If you need cross-functional collaboration and visual agent building: Choose Vellum. It's the most accessible platform for non-engineers, with conversational agent creation and 40+ tool integrations out of the box.
The LLM tooling landscape has matured significantly—teams no longer need to compromise between evaluation rigor, production monitoring, and deployment flexibility. Whether you prioritize open source transparency, enterprise-grade automation, or framework-specific integration, there's a strong alternative to Maxim AI that fits your needs.