Key takeaways
- Technical SEO fundamentals -- crawlability, rendering, structured data, site speed -- still determine what AI search engines can find and cite. AI doesn't route around broken sites.
- Server logs are now more valuable than ever because they reveal a three-way split: indexation bots (Googlebot, Bingbot), training crawlers (GPTBot, ClaudeBot), and AI retrieval bots (OAI-SearchBot, PerplexityBot) all hitting your site with different intentions.
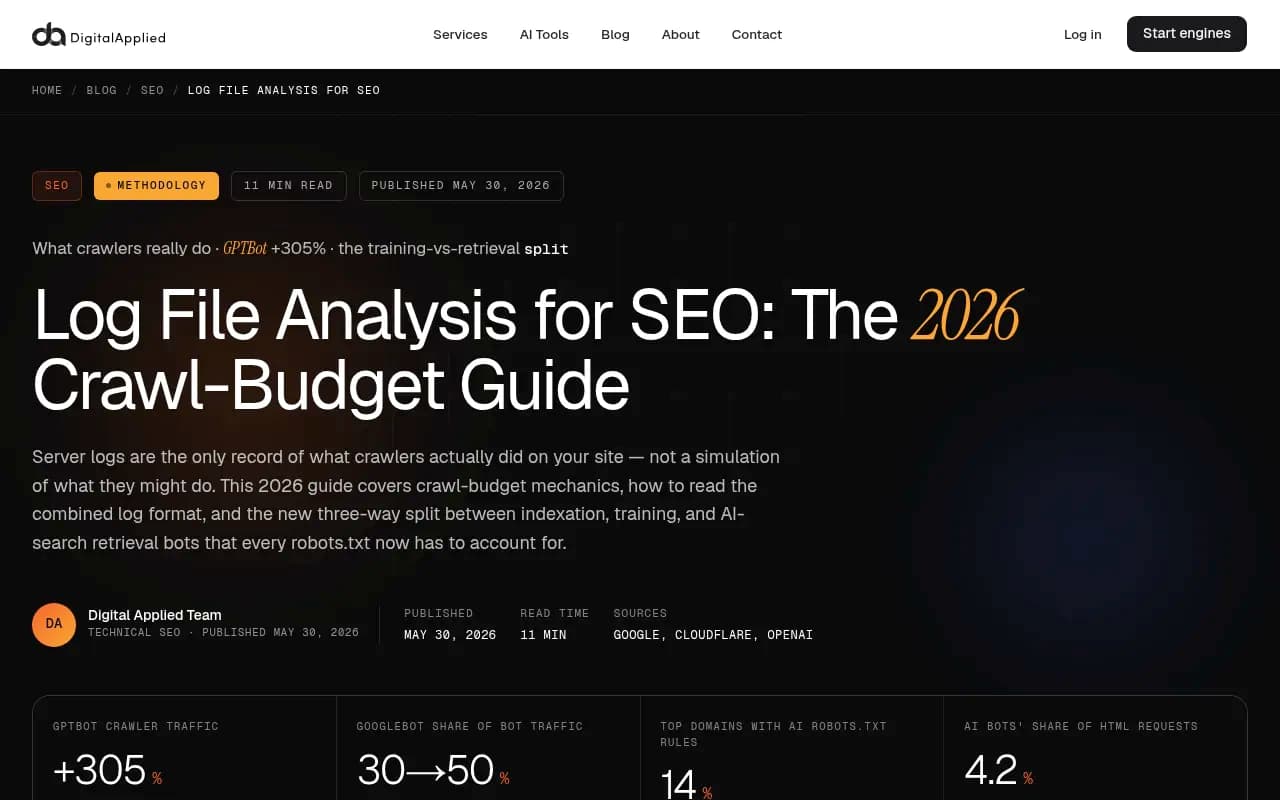
- GPTBot traffic grew 305% year-over-year between May 2024 and May 2025, per Cloudflare data. AI bots averaged 4.2% of all HTML requests across Cloudflare's network in 2025.
- The tools that matter in 2026 are the ones that help you act on what you find -- not just surface another dashboard.
- AI visibility tracking (which prompts you appear in, which pages get cited) is a separate layer on top of technical SEO, not a replacement for it.
Why technical SEO didn't become irrelevant
There's a version of the 2026 narrative where AI search made technical SEO obsolete. The idea goes: if ChatGPT or Perplexity is just synthesizing answers from its training data, why does your robots.txt matter?
It's the wrong model. Google's own documentation is explicit: pages that appear as supporting links in AI Overviews or AI Mode must be indexed and eligible to appear in regular Google Search with a snippet. No special AI layer bypasses that requirement. You can't be cited in an AI Overview if Googlebot can't crawl and index the page in the first place.
The same logic applies to retrieval-augmented systems like Perplexity and ChatGPT's web search. These tools fetch live pages to answer questions. If your important pages are blocked, slow to respond, or hidden behind JavaScript that retrieval bots can't render, you simply won't appear. The AI doesn't work around the mess -- it inherits it.
What changed is the cost of getting it wrong. A technical problem that used to hurt your Google rankings now also removes you from AI-generated answers across multiple platforms simultaneously. The blast radius got bigger.
The new bot landscape: three types of crawlers, one log file
This is the part of technical SEO that changed most dramatically in 2025-2026. Your server logs used to be a conversation between your site and Googlebot, with occasional visits from Bingbot and a few scrapers. Now they record a three-way split:
Indexation bots -- Googlebot, Bingbot, and their rendering variants -- crawl your site to build search indexes. Their behavior is well-documented and their user agents are verifiable. These still matter most for traditional rankings.
Training crawlers -- GPTBot (OpenAI), ClaudeBot (Anthropic), and similar bots -- crawl to collect data for model training. They're not fetching your page to answer a question right now; they're building future knowledge. You can block them in robots.txt if you want, but doing so won't necessarily remove you from AI answers (models trained before the block will still have your content).
AI retrieval bots -- OAI-SearchBot, Claude-SearchBot, PerplexityBot -- fetch pages live to answer user queries. These are the ones that matter most for real-time AI citations. Blocking them means you won't appear in those AI search results, full stop.
Per Cloudflare's network data, GPTBot raw requests grew 305% between May 2024 and May 2025. AI bots averaged 4.2% of all HTML requests across Cloudflare's network, peaking at 6.4%. Googlebot and Bingbot together account for 30-50% of all crawler traffic on most sites.
The practical implication: your robots.txt now needs three separate decisions. What do you want indexation bots to crawl? What do you want training bots to access? What do you want retrieval bots to fetch? These are different questions with different answers depending on your content strategy.
Log analyzers: the tools that show ground truth
Log file analysis is the only technique that shows what crawlers actually did on your site, request by request. Every other source -- Search Console, rank trackers, crawl simulators -- is a model of behavior. The server log is the record.
In 2026, log analysis matters more than it did in 2020 because the bot population is more complex. You need to see which retrieval bots are reaching you, which pages they're fetching, whether they're hitting errors, and how often they return. That's not visible anywhere else.
JetOctopus
JetOctopus handles large-scale log analysis well -- it's built for sites with 10K+ pages where manual log parsing isn't realistic. It segments bot traffic, shows crawl frequency by page type, and surfaces crawl budget waste. For sites getting meaningful AI bot traffic, being able to filter by user agent and see which pages retrieval bots are hitting (versus training bots) is genuinely useful.
OnCrawl
OnCrawl combines log file analysis with crawl data, which means you can cross-reference what bots requested against what your own crawler found. That combination is useful for diagnosing why certain pages aren't being crawled -- is it a crawl budget issue, a robots.txt problem, or something structural about internal linking?
Screaming Frog SEO Spider
Screaming Frog's desktop crawler isn't primarily a log analyzer, but it's worth mentioning here because many teams use it alongside log data. It's the fastest way to audit crawlability, find blocked pages, and check robots.txt directives before you look at whether bots are actually respecting them in your logs.
Site crawlers and technical auditors
Crawl tools simulate what bots see when they visit your site. They're not as definitive as logs, but they're faster to run and easier to interpret for most teams.
Screaming Frog
Still the standard for desktop-based crawling. It's fast, handles JavaScript rendering via a headless browser, and gives you granular control over crawl settings. For checking whether AI retrieval bots can actually read your pages -- which means checking rendered HTML, not just raw source -- Screaming Frog's JavaScript rendering mode is the right tool.
Sitebulb

Sitebulb is worth using if you find Screaming Frog's output hard to interpret. It turns crawl data into prioritized recommendations with visual diagrams of site structure and internal linking. The hint system is particularly good for teams that need to explain technical issues to non-technical stakeholders.
Lumar
Lumar (formerly Deepcrawl) is the enterprise option. It runs scheduled crawls, tracks changes over time, and now includes GEO-specific metrics for AI visibility. For large sites where a single crawl isn't enough -- you need continuous monitoring of crawl health -- Lumar is the right tier.
Botify
Botify sits at the intersection of log analysis and crawling. It ingests real server logs and combines them with its own crawl data, which gives you a more complete picture than either source alone. It's expensive, but for large e-commerce or publisher sites where crawl budget is a real constraint, the combined view is worth it.
DebugBear
DebugBear is primarily a performance monitoring tool, but it belongs in any technical SEO toolkit in 2026. Core Web Vitals still matter for both traditional rankings and AI citation eligibility (slow pages that time out for retrieval bots simply won't be cited). DebugBear catches performance regressions before they become ranking problems.
Performance and rendering tools
JavaScript rendering is one of the most common reasons AI retrieval bots fail to read page content. If your site relies on client-side rendering, the bot may receive an empty HTML shell with no useful text. This is a problem that existed before AI search, but it's now more consequential.
Google PageSpeed Insights
Free, authoritative, and directly tied to how Google evaluates your pages. Run it on your most important pages -- the ones you'd want cited in AI answers -- and fix anything in the "poor" range for LCP and CLS. These aren't just ranking signals; they're signals that a page is reliable enough to fetch and display.
Prerender.io
If your site is JavaScript-heavy and you can't move to server-side rendering, Prerender.io is a practical middle ground. It pre-renders pages and serves the static HTML to bots, which means retrieval bots get readable content even if the live page requires JavaScript execution. This is a technical GEO fix as much as a traditional SEO fix.
SEO4Ajax
Similar to Prerender.io but with a different implementation approach. Worth evaluating if you're on a specific stack where Prerender.io doesn't integrate cleanly.
Structured data and semantic HTML
Structured data is one area where the AI search era genuinely changed the priority order. Schema markup helps AI systems understand what a page is about, who wrote it, what it's claiming, and how to attribute it. This matters for both traditional rich results and for how AI models interpret and cite your content.
WordLift
WordLift focuses specifically on structured data and entity optimization. It helps you build knowledge graphs around your content, which is increasingly relevant as AI models use entity relationships to decide what's authoritative and citable.
Yoast SEO
For WordPress sites, Yoast handles the basics of structured data automatically -- Article schema, breadcrumbs, organization markup. It's not sophisticated, but it removes the most common structured data gaps without requiring developer time.
Rank Math
Rank Math has become a strong alternative to Yoast for WordPress, with more granular schema controls and better support for custom schema types. If you're implementing FAQ schema, HowTo schema, or product markup, Rank Math gives you more control.
Comparison: which technical SEO tools to use for what
| Task | Tool | Best for |
|---|---|---|
| Log file analysis (large sites) | JetOctopus | Sites 10K+ pages, AI bot traffic analysis |
| Log + crawl combined view | OnCrawl, Botify | Enterprise sites with crawl budget issues |
| Desktop crawling and audits | Screaming Frog SEO Spider | Most teams, fast audits |
| Visual audit with recommendations | Sitebulb | Agencies, non-technical stakeholders |
| Enterprise scheduled crawling | Lumar | Large sites, continuous monitoring |
| Performance monitoring | DebugBear | Catching Core Web Vitals regressions |
| Page speed analysis | Google PageSpeed Insights | Quick checks, free |
| JS rendering for bots | Prerender.io | JavaScript-heavy sites |
| Structured data (WordPress) | Rank Math, Yoast SEO | WordPress sites |
| Entity and knowledge graph | WordLift | Content-heavy sites, entity SEO |
| Traditional SEO + site audit | Semrush, Ahrefs | All-in-one platform users |
What technical SEO tools don't cover: AI visibility
Here's the gap that most technical SEO teams hit in 2026: you can have a perfectly crawlable, fast, well-structured site and still not appear in AI search results. Technical SEO is a prerequisite, not a guarantee.
AI visibility -- which prompts trigger your content, which pages get cited, how often your brand appears in ChatGPT or Perplexity responses -- requires a different layer of tooling. This is where GEO (Generative Engine Optimization) platforms come in.
Promptwatch is one platform that bridges this gap. Where technical SEO tools tell you whether bots can reach your pages, Promptwatch tells you whether AI models are actually citing them -- and which content gaps are preventing citations in the first place. Its AI Crawler Logs feature shows real-time data on which AI crawlers are hitting your site, which pages they're reading, and when pages move from crawl to citation. That's the kind of visibility that server log analysis alone can't give you.

For teams that want to track AI visibility without the full GEO platform investment, there are lighter options:
Semrush has added AI Overviews tracking to its existing platform. It's useful if you're already a Semrush user and want a single dashboard, though its AI search coverage is narrower than dedicated GEO tools.
Ahrefs has Brand Radar for tracking brand mentions in AI responses. It covers fewer AI models than dedicated platforms and lacks traffic attribution, but it's a reasonable starting point for teams already in the Ahrefs ecosystem.
The robots.txt conversation you need to have in 2026
Most sites haven't updated their robots.txt since AI retrieval bots became a meaningful traffic source. That's a problem, because the default behavior -- allowing all bots -- may not be what you actually want.
A few decisions worth making explicitly:
Do you want training crawlers (GPTBot, ClaudeBot) to access your content? Blocking them prevents future model training on your content but doesn't remove you from current AI answers. Some publishers have blocked them; most commercial sites haven't.
Do you want retrieval bots (OAI-SearchBot, PerplexityBot) to fetch your pages? Blocking these removes you from real-time AI search results. For most brands, this is the wrong call.
Are you accidentally blocking retrieval bots with overly broad disallow rules? This is the most common problem. A rule written to block scrapers may also be blocking legitimate AI retrieval bots. Check your logs to see which bots are being blocked and whether that's intentional.
The only way to answer these questions with confidence is to look at your actual log data -- not a crawl simulation.
LLMs.txt: worth implementing, but not a magic fix
LLMs.txt is a proposed standard (similar in spirit to robots.txt) that lets site owners signal to AI systems which content is appropriate for training or retrieval. As of mid-2026, support is inconsistent across AI platforms, but implementation is low-effort and the potential upside is real.
The file lives at yourdomain.com/llms.txt and contains structured information about your site's content, intended use, and any restrictions. Think of it as a machine-readable content policy for AI systems.
It won't fix a site that's technically broken. But for a site that's already technically sound, it's a reasonable signal to add.
What to audit first in 2026
If you're prioritizing a technical SEO audit with AI search in mind, here's a practical order:
- Check your robots.txt against the known AI bot user agents. Verify you're not accidentally blocking retrieval bots.
- Pull your server logs and segment by bot type. See which AI retrieval bots are reaching you, which pages they're hitting, and whether they're encountering errors.
- Run a crawl of your most important pages in JavaScript rendering mode. Confirm that the rendered HTML contains the content you want AI systems to read.
- Check Core Web Vitals on those same pages. Pages that time out or load slowly for retrieval bots won't be cited.
- Audit your structured data. At minimum, implement Article or WebPage schema on your key content pages, with author and organization markup.
- Add or update your llms.txt file.
Then -- separately -- start tracking which prompts you're actually appearing in. Technical SEO gets you in the game. GEO tracking tells you whether you're winning.
The tools that matter in 2026 are the ones that help you act on what you find. A log analyzer that surfaces AI bot errors is useful. A crawl tool that shows you JavaScript rendering failures is useful. A GEO platform that shows you which content gaps are costing you citations -- and helps you close them -- is what connects technical work to actual results.